JVM性能优化实践-读书笔记-第8章
8.垃圾收集日志,监控,调优及工具
8.1 认识垃圾收集日志
应用程序应该做到:
- 产生垃圾收集日志
- 垃圾收集日志落盘
8.1.1 开启垃圾收集日志记录
必须打开垃圾收集标志
| 标志 | 作用 |
|---|---|
| -Xloggc:gc.log | Controls which file to log GC events to 控制垃圾日志应该写入哪个文件 |
| -XX:+PrintGCDetails | Logs GC event details 将垃圾收集的详细事件写入日志 代替了旧的 verbose:gc标志 |
| -XX:+PrintTenuringDistribution | Adds extra GC event detail that is vital for tooling 添加对工具重要的垃圾收集事件额外细节 提供了原始数据,需要工具处理。 |
| -XX:+PrintGCTimeStamps | Prints the time (in secs since VM start) at which GC events occurred 输出发生时间 将垃圾收集事件与应用程序关联 |
| -XX:+PrintGCDateStamps | Prints the wallclock time at which GC events occurred 打印垃圾收集时间的挂钟时间 将垃圾收集事件与JVM事件关联 |
垃圾收集日志滚动标志
标志 | 作用
—|—
-XX:+UseGCLogFileRotation | 打开日志文件滚动
-XX:+NumberOfGCLogFiles=
日志文件的最大值
8.1.2 垃圾收集日志与JMX的对比
| 因素 | 垃圾收集日志 | JMX |
|---|---|---|
| 来源 | 实际垃圾收集事件驱动 | 通过采样获得 |
| 成本 | 很低 | 有代理和远程方法调用成本 |
| 数据 | 与内存管理相关的50+数据 | 不到10个 |
JMX最大优点是开箱即用
8.1.3 JMX的缺点
JMX通过轮询机制实现。
- 无法知道收集器何时运行,每个收集周期前后的内存状态都是未知的。
- 无法进行精确分析。
- 长期趋势观察是有用的。
- 无法跟踪分配率。
JMX通过RMI实现,RMI的问题:
- 需要配置防火墙相应端口
- 使用代理对象以方便调用
remove()方法 - 依赖于Java的终结化机制(
finalization)
8.1.4 垃圾收集日志数据带来的好处
垃圾收集日志在Hotspot内使用非阻塞写入机制完成,对应用程序的性能没有影响。
浮现式(emergent)系统 系统的最终行为和性能是所有共同工作和执行的结果,不同的压力会以不同方式影响不同组件,从而导致成本模型也会动态发生变化。
现代垃圾收集器包含很多不同组件,是一个浮现式系统,每个收集器的行为和性能是不可预测的,因此要通过垃圾收集日志来分析。
8.2 日志解析工具
8.2.1 Censum
- 由jClarity 开发的商业工具,似乎作者还挺喜欢
- 2019年被微软收购了。。。
- 目前是开源产品,地址: https://github.com/microsoft/gctoolkit
这个,哈哈哈哈,相关连接在文末参考的部分,祝好吧。
8.2.2 GCViewer
- 开源工具,免费使用
- 桌面端软件,功能有限。
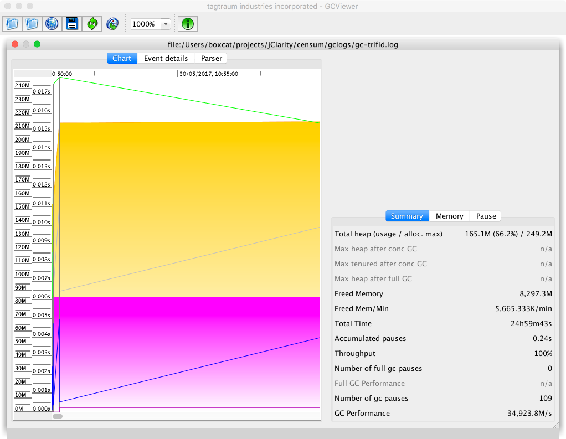
8.3 基本垃圾收集调优
一些事实
- 排除或确认垃圾收集是性能问题的根源所付出的成本很低;
- 在用户验收测试中开启垃圾收集日志成本很低(国内应该对应的是
生产环境); - 设置及执行内存剖析器的成本不低。
调优关注的因素
- 分配
最重要的因素
- 暂停的灵敏度
- 吞吐量
- 对象生命周期
设置GC堆大小 Flag | Effect —|— -Xms<size> | 堆的最小值 -Xmx<size> | 堆的最大值 -XX:MaxPermSize=<size> | 设置 PerGen最大值 (Java 7) -XX:MaxMetaspaceSize=<size> | 设置 Metaspace 最大值(Java 8)
调优准则
- 每次只添加或修改一个标志
- 确保理解每个标志的效果
- 记住有些组合会产生副作用
确认垃圾收集是性能问题的根源
- CPU 利用率接近100%;
- 时间的绝大部分(90%以上)在用户空间中消耗;
- 垃圾收集日志一直有活动.
8.3.1 理解分配行为
可以使用新生代收集事件中的数据来计算分配的数据量和两次收集之间的时间,来计算分配率。 借助工具实现。
经验表明,持续超过1Gb/s的分配率大部分是有问题的,并且这些问题需要系统调优(重构软件)来进行,而非JVM调优
优化点
- 不要重要,可避免的对象对分配
- 日志信息
- 自动生成的序列化/反序列化代码
- ORM代码
- 装箱开销
- 领域对象
- 领域对象通常不是内存开销贡献者
- 大多数为
char[],byte[],double[],Map,Object[],内部数据结构(OOp) - 大数组有可能直接被分配在Tenured
- 大量非JDK框架对象
与Tenured有关的JVM标志
| Flag | Effect |
|---|---|
| -XX:PretenureSizeThreshold=<n> | 大于这个值的参数直接在老年代分配 |
| -XX:MinTLABSize=<n> | |
| -XX:MaxTenuringThreshold=<n> | 对象晋升到Tenured前必须经历的垃圾收集次数 (默认4,可以设置为1-15) |
8.3.2 理解暂停时间
应用程序容忍的暂停时间:
- 大于1s
- 100ms–1s
- 小于100ms
初始收集器选择与配置
1 s 1 s–100 ms <100 ms 堆大小 Parallel Parallel CMS < 4 GB Parallel Parallel/G1 CMS < 4 GB Parallel Parallel/G1 CMS < 10 GB Parallel/G1 Parallel/G1 CMS < 20 GB Parallel/G1 G1 CMS > 20 GB
8.3.3 收集线程和GC根
像垃圾收集器一样思考
GC 扫描的时间影响因素
- 应用程序线程数量
- 代码缓存中已经编译的代码量
- 堆的大小
模拟卡表扫描
使用代码模拟在堆20Gb情况下扫描卡表所需要的时间
卡表相关的内容参见第六章
@State(Scope.Benchmark)
@BenchmarkMode(Mode.Throughput)
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@OutputTimeUnit(TimeUnit.SECONDS)
@Fork(1)
public class SimulateCardTable {
// OldGen is 3/4 of heap, 2M of card table is required for 1G of old gen
// 老年代 为堆大小的 4/3 ,每1G空间需要2Mb的卡表大小
// 卡表中的一个字节代表老年代的512 字节
private static final int SIZE_FOR_20_GIG_HEAP = 15 * 2 * 1024 * 1024;
private static final byte[] cards = new byte[SIZE_FOR_20_GIG_HEAP];
@Setup
public static final void setup() {
final Random r = new Random(System.nanoTime());
for (int i=0; i<100_000; i++) {
cards[r.nextInt(SIZE_FOR_20_GIG_HEAP)] = 1;
}
}
@Benchmark
public int scanCardTable() {
int found = 0;
for (int i=0; i<SIZE_FOR_20_GIG_HEAP; i++) {
if (cards[i] > 0)
found++;
}
return found;
}
public static void main(String[] args) {
Options opt = new OptionsBuilder().include(SimulateCardTable.class.getSimpleName())
.warmupIterations(100)
.measurementIterations(5)
.forks(1)
.jvmArgs("-server", "-Xms2048m", "-Xmx2048m", "-verbose:gc")
.addProfiler(GCProfiler.class)
.addProfiler(StackProfiler.class)
.build();
try {
new Runner(opt).run();
} catch (RunnerException e) {
e.printStackTrace();
}
}
}
输出
# Benchmark: com.github.yfge.SimulateCardTable.scanCardTable
# Run progress: 0.00% complete, ETA 00:01:45
# Fork: 1 of 1
[0.008s][info][gc] Using G1
# Warmup Iteration 1: 122.164 ops/s
# Warmup Iteration 2: 126.087 ops/s
# Warmup Iteration 3: 127.965 ops/s
# Warmup Iteration 4: 127.243 ops/s
# Warmup Iteration 5: 127.483 ops/s
# Warmup Iteration 6: 128.097 ops/s
# Warmup Iteration 7: 127.838 ops/s
# Run complete. Total time: 00:02:40
REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on
why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial
experiments, perform baseline and negative tests that provide experimental control, make sure
the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts.
Do not assume the numbers tell you what you want them to tell.
Benchmark Mode Cnt Score Error Units
SimulateCardTable.scanCardTable thrpt 5 127.022 ± 5.205 ops/s
结论是对于20G的堆,扫描卡表时间大约为1/127 秒即 8 毫秒左右
书上例子为 10ms
8.4 调优Parallel GC
目标与取舍
- 完全STW
- 吞吐量高/计算成本低
- 不可能出现部分收集
- 暂停时间随着堆大小纯属增加
8.5 调优CMS
对于大多数CMS的应用,可能不并不能修改CMS标志来获得可见性的性能改进。
背靠背收集 CMS在收集时,有一半的处理器在运行收集线程,如果一次垃圾收集结束后会立刻启动下一次,这种情况下被称为背靠背收集,在这种情况下,会损失50%的性能。
CMS一些标志 Flag | Effect —|— -XXConGCThreads=<n> | 分配给收集线程的核心数量 -XX:CMSInitiatingOccupancyFraction=<n> | 堆到达到这个大小时第一次FullGC,默认75% -XX:+UseCMSInitiatingOccupancyOnly | 引发FullGC的内存比例是否动态调整
对于一些分配率比较高的程序,一种策略是在关闭自适应大小的同时增加净空间,可以减少迸发模式失败,但会增加垃圾收集的频率。
8.6 调优G1
原则
- 将新生代设置的较大
- 增加晋升阈值,考虑设置成最大值(15)
- 设置该应用程序可以容忍的最长暂停时间
8.7 jHiccup
与HdrHistogram配套使用的工具,可以用来显示JVM无法连续运行的间隔(Hiccup)
会产生Hlog文件,可以用jHiccup提供的工具jHiccupLogProcessor进行查看分析。
开启方式:
- 注入:
jHiccup -p <pid> - 代理:
-javaagent:jHiccup.jar
一个集成jHiccup的脚本:
#!/bin/bash
# Simple script for running jHiccup against a run of the model toy allocator
CP=./target/optimizing-java-1.0.0-SNAPSHOT.jar
JHICCUP_OPTS=
-javaagent:~/.m2/repository/org/jhiccup/jHiccup/2.0.7/jHiccup-2.0.7.jar
GC_LOG_OPTS="-Xloggc:gc-jHiccup.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps -XX:+PrintTenuringDistribution"
MEM_OPTS="-Xmx1G"
JAVA_BIN=`which java`
if [ $JAVA_HOME ]; then
JAVA_CMD=$JAVA_HOME/bin/java
elif [ $JAVA_BIN ]; then
JAVA_CMD=$JAVA_BIN
else
echo "For this command to run, either $JAVA_HOME must be set, or java must be
in the path."
exit 1
fi
exec $JAVA_CMD -cp $CP $JHICCUP_OPTS $GC_LOG_OPTS $MEM_OPTS
optjava.ModelAllocator”
查看分析
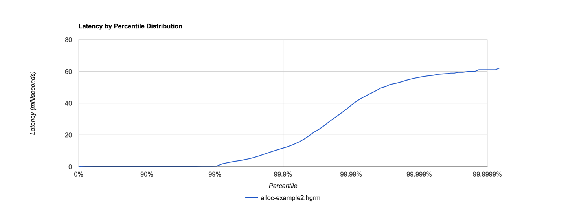
jHiccupLogProcessor -i hiccup-example2.hlog -o alloc-example2
类似下图:
参考
远程方法调用 https://baike.baidu.com/item/远程方法调用
CenSum / MS GC Toolktit https://github.com/microsoft/gctoolkit
Introducing Microsoft GCToolkit https://devblogs.microsoft.com/java/introducing-microsoft-gctoolkit/
-XX:PretenureSizeThreshold 的默认值和作用 https://www.jianshu.com/p/f7cde625d849
jHiccup https://github.com/giltene/jHiccup
关于老拐瘦
中年争取不油不丧积极向上的码农一名
咖啡,摄影,骑行,音乐
样样通,样样松
喜欢可以关注一下公众号 IT老拐瘦

目前个人博客长驻: yfge.github.io