JVM性能优化实践-读书笔记-第9章
9.JVM 上的代码执行
Java 虚拟机规范描述了符合规范的Java实现需要如何执行代码
9.1 字节码解释概述
JVM以栈式机器的方式运行;
JVM提供的三个主要存储区
- 求值栈 属于特定方法的本地
- 用于临时存储结果的局部变量(也属于方法本地)
- 对象堆 在方法和线程间共享
栈式计算的举例
计算 ` if x < 3 + 1 `的过程:
初始状态:
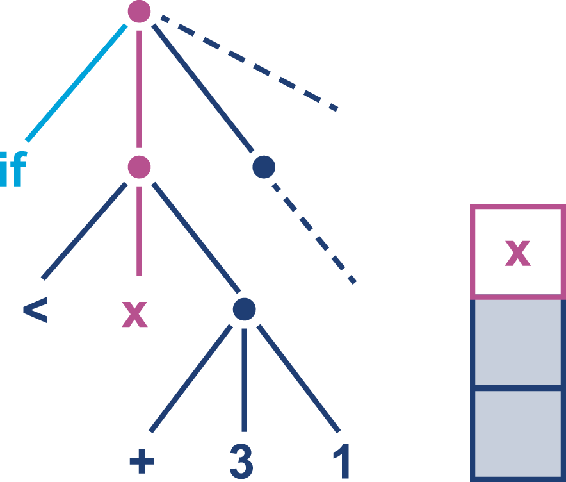
计算右侧子树,3进栈
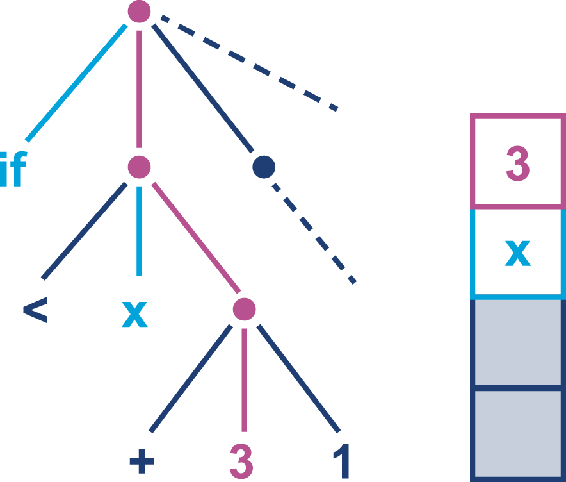
1继续进栈
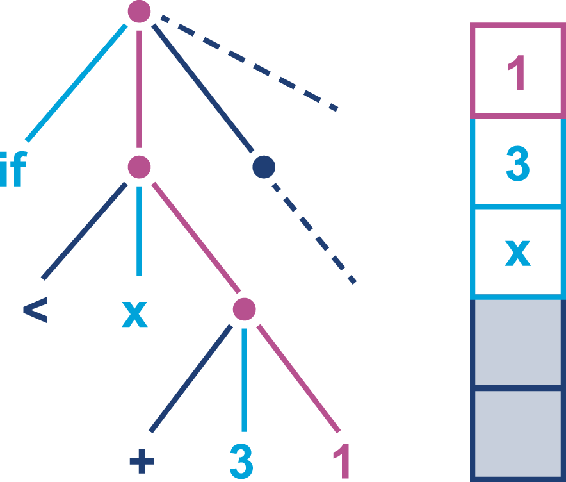
对栈顶的两个值进行计算
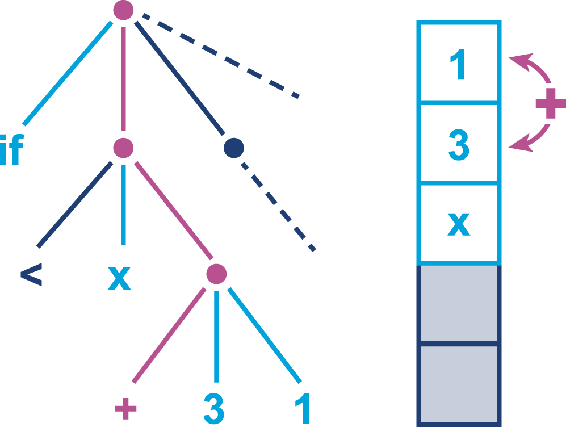
得到的4进栈,之后进行下一步
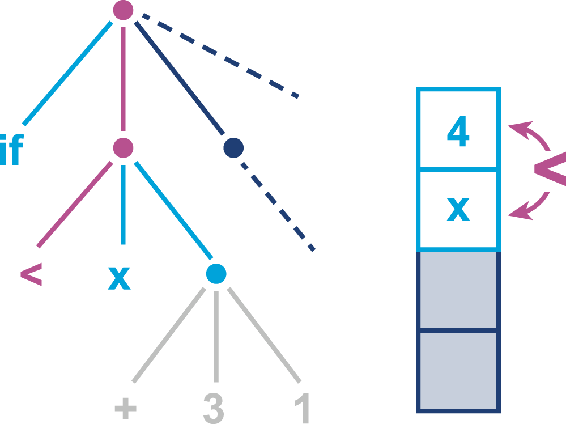
拐言: 虽然这个图其实和整体这一章没啥关系,但墙裂建议细嚼慢用,理解这部分对一些内容,比如力扣上的一些表达式求值,括号匹配之类的,大有精进
9.1.1 JVM字节码
- 字节码: 在JVM中,每一个栈式机器操作码(opcode)用一字节表示,称为字节码(bytecode)
- 范围 0-255
- 带类型信息的,如
iadd和dadd - 很多以”家族”形式出现,n条用于基本类型,1条用于对象引用
- 选择大端(
big-endian)方式,高位优先 - 操作码有简洁形式,允许省略参数,如
load和aload_0,后者为将当前对象放到栈顶,少了一个参数
“简洁形式和具体类型指令增加了操作码数量”
主要操作码类别:
加载和保存
英语为原版内容
| 操作码家族名 | 参数 | 描述 |
|---|---|---|
| load | (i1) | Loads value from local variable i1 onto the stack 将局部变量 i1加载到栈顶 |
| store | (i1) | Stores top of stack into local variable i1 将栈顶的值保存到局部变量 i1中 |
| ldc | c1 | Loads value from CP#c1 onto the stack 将常量池中的 c1的值加载到栈顶 |
| const | Loads simple constant value onto the stack 将简单常量值加载到栈上 |
|
| pop | Discards value on top of stack 抛弃栈顶的值 |
|
| dup | Duplicates value on top of stack 复制栈顶的值 |
|
| getfield | c1 | Loads value from field indicated by CP#c1 in object on top of stack onto the stack 将位于栈顶的对象中的以常量池c1的位置指示的字段加载到栈上 |
| putfield | c1 | Stores value from top of stack into field indicated by CP#c1 将栈顶的值保存到以常量池c1位置指示的字段 中 |
| getstatic | c1 | Loads value from static field indicated by CP#c1 onto the stack 将以常量池c1位置指示的静态字段中的值加载到栈上 |
| putstatic | c1 | Stores value from top of stack into static field indicated by CP#c1 将栈顶的值保存到以常量池c1位置指示的静态字段中 |
ldc 与 const的区别
- ldc 从当前类的常量池中加载常量
- const 加载数值固定的真常量 (
aconst_null,dconst_0,iconst_m1(-1))
算术操作码
| 操作码家族名 | 描述 |
|---|---|
| add | Adds two values from top of stack 栈顶两个值相加 |
| sub | Subtracts two values from top of stack 栈顶两个值相减 |
| div | Divides two values from top of stack 栈顶两个值相除 |
| mul | Multiplies two values from top of stack 栈顶两个值相乘 |
| (cast) | Casts value at top of stack to a different primitive type 将栈顶值强制转为一个不同的基本类型 |
| neg | Negates value at top of stack 对栈顶值求反 |
| rem | Computes remainder (integer division) of top two values on stack 栈顶两个值取模 |
流程控制
操作码家族名 | 参数 | 描述
—-|—-|—-
if | (i1) |Branch to the location indicated by the
argument, if the condition is true
如果条件为true,跳转到i1
goto | i1 | Unconditional branch to the supplied offset
跳转到i1
tableswitch | | Out of scope
本书不讨论
lookupswitch | | Out of scope
本书不讨论
方法调用
| 操作码家族名 | 参数 | 描述 |
|---|---|---|
| invokevirtual | c1 | Invokes the method found at CP#c1 via virtual dispatch 通过虚拟分派 (virtual dispatch) 调用在常量池c1找到的方法 |
| invokespecial | c1 | Invokes the method found at CP#c1 via “special” (i.e., exact) dispatch 通过特殊分配(or 精确分派)调用在常量池c1位置找到的方法 |
| invokeinterface | c1, count, 0 | Invokes the interface method found at CP#c1 using interface offset lookup 使用接口位移查找,调用在常量池C1位置找到的方法 |
| invokestatic | c1 | Invokes the static method found at CP#c1 调用在常量池c1位置的静态方法 |
| invokedynamic | c1, 0, 0 | Dynamically looks up which method to invoke and executes it 动态查找要调用的方法并执行该方法 |
- 调用点 一个方法被另一个方法调用,这个位置为称为调用点,被调用的对象称为接收者对象(receiver object),其运行时类型被称为接收者类型(receiver type)
- 对静态方法的调用总为
invokestatic,并且没有接收对象 - 对象方法调用会转成三种可能的字节码(invokevirtual,invokespecial,invokeinterface)
- 实例方法 invokevirtual,静态类型是接口类型 invokeinterface,private或父类调用 invokespecial
- invokedynamic —-lamda 表达式,或在其他JVM上的运行的非JAVA语言
代码示例
public class LambdaExample {
private static final String HELLO = "Hello";
public static void main(String[] args) throws Exception {
Runnable r = () -> System.out.println(HELLO);
Thread t = new Thread(r);
t.start();
t.join();
}
}
操作码如下:
public static void main(java.lang.String[]) throws java.lang.Exception;
Code:
0: invokedynamic #2, 0 // InvokeDynamic #0:run:()Ljava/lang/Runnable;
5: astore_1
6: new #3 // class java/lang/Thread
9: dup
10: aload_1
11: invokespecial #4 // Method java/lang/Thread.
// "<init>":(Ljava/lang/Runnable;)V
14: astore_2
15: aload_2
16: invokevirtual #5 // Method java/lang/Thread.start:()V
19: aload_2
20: invokevirtual #6 // Method java/lang/Thread.join:()V
23: return
平台操作码
| 操作码家族名 | 参数 | 描述 |
|---|---|---|
| new | c1 | Allocates space for an object of type found at CP#c1 为在常量池c1位置的对象所找到的类型分配空间 |
| newarray | prim | Allocates space for a primitive array of type prim 为prim类型的基本类型数组分配空间,长度为栈顶 |
| anewarray | c1 | Allocates space for an object array of type found at CP#c1 为在常量池c1位置找到的类型的对象数组分配空间 长度为栈顶 |
| arraylength | Replaces array on top of stack with its length 获得栈顶的数组的长度,并将其置到栈顶 |
|
| monitorenter | Locks monitor of object on top of stack 锁定栈顶对象的管程 |
|
| monitorexit | Unlocks monitor of object on top of stack 解锁顶对象的管程 |
当一个操作码被分派时,JVM一定是在执行解释器,而不是用户代码,这时堆是一个稳定态,因此是一个可以暂停的安全点
9.2 简单的解释器
文中线了一个简单的解释器的代码模拟:
拐言:
这段代码非常值得一读, 中间有几个有意思的点已经加注释。
/**
* instr 是要执行的内存块
* 这个内存块显然是一块连续的数据,里面即有变量位置,也有字节码
**/
public EvalValue execMethod(final byte[] instr) {
if (instr == null || instr.length == 0)
return null;
EvaluationStack eval = new EvaluationStack();
/**
* current 就是当前执行的位置,可以理解成指令偏移
*/
int current = 0;
LOOP:
while (true) {
// 读到一个值,即当前的字节码
byte b = instr[current++];
// 通过查表的方式得到字节码值
// 这里table 保存了所有的字节码集合
// b & 0xff 是因为字节码为0-255
Opcode op = table[b & 0xff];
if (op == null) {
System.err.println("Unrecognized opcode byte: " + (b & 0xff));
System.exit(1);
}
// 要知道这个字节码有几个参数
byte num = op.numParams();
switch (op) {
case IADD:
eval.iadd();
break;
case ICONST_0:
eval.iconst(0);
break;
// ...
case IRETURN:
// 将栈顶值返回
return eval.pop();
case ISTORE:
// 将栈顶值保存到当前值
// 注意这里因为current ++ 是下一个位置
// 因为store有两个参数
istore(instr[current++]);
break;
case ISUB:
eval.isub();
break;
// Dummy implementation
// 这下面的指令都有多个参数
case ALOAD:
case ALOAD_0:
case ASTORE:
case GETSTATIC:
case INVOKEVIRTUAL:
case LDC:
System.out.print("Executing " + op + " with param bytes: ");
// 在内存中接着步进num步,把相应的参数取出来作为指令的参数
for (int i = current; i < current + num; i++) {
System.out.print(instr[i] + " ");
}
// 执行指针步进num
// 因为相应的参数已经读取完了
// 所以下一个字节(内存中的数据)还是一个字节码(可执行的指令)
current += num;
System.out.println();
break;
case RETURN:
return null;
default:
System.err.println("Saw " + op + " : can't happen. Exit.");
System.exit(1);
}
}
}
9.1.3 HotSpot的一些细节
- HotSpot是一块模板解释器(
template interpreter) - HotSpot定义了没有在JVM规范中的字节码,用于区分热点情况和某个特定操作码更一般的使用情况
关于final
因为final不能被覆盖,所以final在译成字节码时是可以为invokespacial的,但这会违反里氏替换原则,因此就当为invokevirtual,而HotSpot专门为final配置了一个字节码。
解释:
先有:
将一个声明为final的方法改为不用final修饰,不会破坏与现有二进制文件的兼容性
—- Java语言规范 13.4.7节
比如有代码
代码A的定义
public class A {
public final void fMethod() {
// ... do something
}
}
调用方的定义
public class CallA {
public void otherMethod(A obj) {
obj.fMethod();
}
}
- 这里obj.fMethod因为是final的,所以看上去可以用invokespacial 来处理。
但是如果A的final去掉了,同时有b继承a,并重写了fMethod,这里时如果传入otherMethod是一个b的对象,这时调用就会出错。
同时,因为根据将一个声明为final的方法改为不用final修饰,不会破坏与现有二进制文件的兼容性,也就是说,A改变后,不会影响CallA,所以,这里不能用invokespecial.
关于终结机制(finalization)
如果一个对象有终结机制,则必须到终结子系统中的注册,并且该注册必须在超类的构造器调用完后立刻执行。
Java语言规范
- 增加一个私有字节码,用于表示Object构造器的返回。
9.2 AOT编译和JIT编译
9.2.1 AOT编译(Ahead of Time )
即静态编译,比如C或C++
- 只有一次编译
- 只有一次机会(即编译)来进行潜在优化
9.2.2 JIT编译
JIT(Just-In-Time)编译其实是一种通用的技术,即程序(大多数为中间格式,比如.class)在运行时被转化为高度优化的机器代码
JIT会在运行时收集程序信息,进行性能剖析(profile),用以确定程序哪部分使用频率最高且优化收益最大,因此也被称为剖析制导优化。(profile-guided optimization,PGO)
因为JIT与应用程序同时运行,因此JIT的执行成本要和预期收入保持平衡。
剖析是运行时的结果 ,同时,HotSpot不会保存任何剖析,会在下次运行时重新执行。
9.2.3 AOT和JIT的比较
AOT
- 相对简单
- 与汇编代码对应,可以获利机器的直接性能特性
- 放弃了运行时的优化可能
- 针对处理器优化,可以满足极端性能要求
- 不易扩展
JIT
- 可以针对处理器优化,不必重新编译
- 部分商用JVM也有AOT
- JAVA9开始,已经提供AOT编译功能
9.3 HotSpot JIT基础
- 编译的基本单元是方法
- 如果方法A本身有一个循环,循环内有一个方法B,如果A没达到编译要求,可以先编译B,这种技术被称为栈上替换(on-stack-replacement,OSR)
这时B应该已经达到编译要求? 感觉这段晕乎
原文:
OSR is used to help the case where a method is not called frequently enough to be compiled but contains a loop that would be eligible for compilation if the loop body was a method in its own right
9.3.1 Klass字,虚函数表和指针变换
单个方法的简单编译如下图:
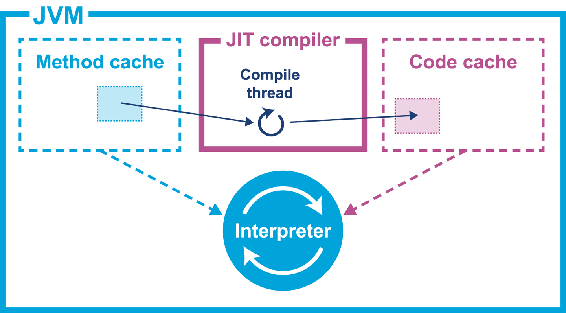
即当一个方法需要优化时,会通过JIT编译器优化后保存到代码缓存中,此时相关Klass中虚函数表(vtable)的条目会更新,以指向新的代码。
vtable的这种更新被称为指针变换(pointer swizzling)
9.3.2 JIT编译日志
-XX:PrintCompilation 打开编译日志
ex
java -XX:+PrintCompilation optjava.Caching 2>/dev/null
输出:
56 1 3 java.lang.Object::<init> (1 bytes)
57 2 3 java.lang.String::hashCode (55 bytes)
58 3 3 java.lang.Math::min (11 bytes)
59 4 3 java.lang.String::charAt (29 bytes)
60 5 3 java.lang.String::length (6 bytes)
60 6 3 java.lang.String::indexOf (70 bytes)
60 7 3 java.lang.AbstractStringBuilder::ensureCapacityInternal (27 bytes)
60 8 n 0 java.lang.System::arraycopy (native) (static)
60 9 1 java.lang.Object::<init> (1 bytes)
60 1 3 java.lang.Object::<init> (1 bytes) made not entrant
61 10 3 java.lang.String::equals (81 bytes)
66 11 3 java.lang.AbstractStringBuilder::append (50 bytes)
67 12 3 java.lang.String::getChars (62 bytes)
68 13 3 java.lang.String::<init> (82 bytes)
74 14 % 3 optjava.Caching::touchEveryLine @ 2 (28 bytes)
74 15 3 optjava.Caching::touchEveryLine (28 bytes)
75 16 % 4 optjava.Caching::touchEveryLine @ 2 (28 bytes)
76 17 % 3 optjava.Caching::touchEveryItem @ 2 (28 bytes)
第一列 编译时间
第二列 编译顺序
其他说明
- n 方法是原生的
- s 方法是同步的
- !方法有异常处理程序
- % 方法通过栈上替换编译
可以通过 -XX:+LogCompilation -XX:+UnlockDiagnosticVMOptions 来得到一个xml的详细日志,其中LogCompilation为编译的详细日志,UnlockDiagnosticVMOptions为打开诊断选项。
9.3.3 HotSpot中的编译器
HotSpot中的编译器:
- C1 用于GUI和其他客户端
- C2 用于服务器
都依赖方法被调用的次数或调用计数(invocation count)
C1 简单,编译时间短,不像C2那样充分优化
共用的技术: 静态单一赋值(static single assignment,SSA ),每个变量只被赋值一次,不会重新赋值,即javap被重写为只包括final变量。
9.3.4 HotSpot中的分层编译(Tiered Compliation)
- 第0层 解释器
- 第1层 C1 开启全部优化,不开启剖析
- 第2层 C1 支持调用和回边计数器
- 第3层 C1 开启全部剖析器
- 第4层 C2
编译路径
| 路径 | 描述 |
|---|---|
| 0-3-4 | 解释器,开启全部剖析功能的C1,C2 |
| 0-2-3-4 | 解释器,在C2忙禄的情况下,快速用C1编译,然后是完全编译的C1,然后是C2 |
| 0-3-1 | 简单方法 |
| 0-4 | 无分层编译,即直接到C2 |
9.4 代码缓存
代码缓存 JIT编译的代码被存储的内存区域
代码缓存同时存储了虚拟机本身的其他原生代码,比如解释器部分内容
代码缓存被实现为一个堆,有未分配区域和空闲链表
当原生代码被删除时,相应块被加到空闲列表块,同时有清扫进程(sweeper)来回收块。
存储新的原生方法:
- 从空闲链表中找一个足够大的块
- 从未分配空间中创建一个新块
原生代码被删除的情况:
- 被取消了优化(基于某种假设进行了推测性优化,结果证明条件不成立)
- 被替换成另一个版本(分层编译的情况下)
- 包含该方法的类被卸载了
可以使用如下开关控制代码缓存的最大值:
-XX:ReservedCodeCacheSize=<n>
碎片
C1结果被C2优化后移除,会产生大量碎片
9.5 简单JIT调优
- 打开
PrintCompilation开关 - 收集显示哪些方法被编译的日志
- 通过
ReservedCodeCacheSize增加代码缓存 - 重新运行程序
- 查看缓存增大后已编译的方法的集合
关于老拐瘦
中年争取不油不丧积极向上的码农一名
咖啡,摄影,骑行,音乐
样样通,样样松
喜欢可以关注一下公众号 IT老拐瘦

目前个人博客长驻: yfge.github.io