JVM性能优化实践-读书笔记-第12章
12. 并发性能技术
我们都知道摩尔定律—
摩尔定律: 芯片上的晶体管数量18个月会增加一倍
这持续了50年,但现难以为继;
进一步,这使人们不能再通过使用更大或更新的机器来解决软件性能问题
因此带来的问题是技术耗尽,程序员转而更关注底层技术
拐言: 然而国内的大厂还在各种堆资源,呵呵呵。。。
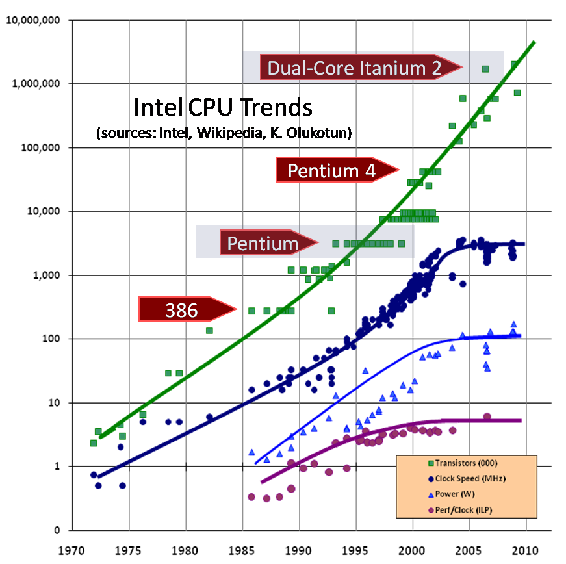
The Free Lunch Is Over(Sutter,2005)
12.1 并行介绍
Amdahl定律
阿姆达尔曾致力于并行处理系统的研究。对于固定负载情况下描述并行处理效果的加速比s,阿姆达尔经过深入研究给出了如下公式:
S=1/((1-a)+a/n)
其中
- a为并行计算部分所占比例
- n为并行处理结点个数。
这样,当1-a=0时,(即没有串行,只有并行)最大加速比s=n;当a=0时(即只有串行,没有并行),最小加速比s=1;当n→∞时,极限加速比s→ 1/(1-a),这也就是加速比的上限。例如,若串行代码占整个代码的25%,则并行处理的总体性能不可能超过4。这一公式已被学术界所接受,并被称做“阿姆达尔定律”,也称为“安达尔定理”(Amdahl law)。
另一种表述为,如果串行的部分为S,任务所需的总时间为T,把处理器个数表示为N,这时,完成这个任务需要的总时间为:
T(N) = S + (1/N)*(T-S)
由此,在这种情况下,Amdahl定律演化为如下图:
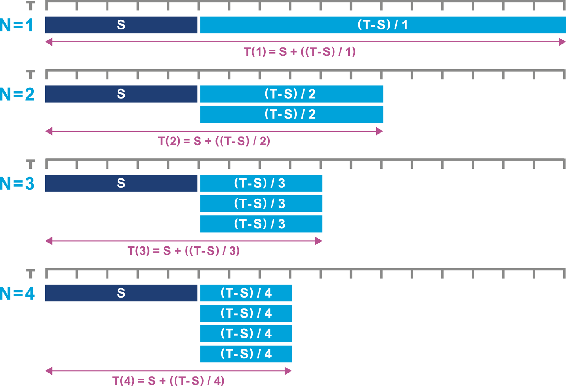
Amdahl定律实际上已经是软件扩展的极限。
如果把T和S都看成任务的个数,即
- T 可以并行执行,互相不影响的任务个数
- S 需要串行执行的任务个数
那么很容易得到Amdahl定律的推论
Amdahl定律推论:
如果并行任务之间没有通信或其他顺序处理,理论上可以无限提升速度
这种情况被称为自然并行(embarrassingly parallel)
而如果并行任务之间需要通信,复杂度就会增加,并增加通信和串行处理的开销。
写出正确的程序很难,写出正确的并发程序更难。与顺序程序相比,并发程序中可能出错的事情会更多。
—-《Java并发编程实践》,Brian Goetz等。
基本Java并发
考虑代码:
public class Counter {
private int i = 0;
public int increment() {
return i = i + 1;
}
}
其字节码如下:
public int increment();
Code:
0: aload_0
1: aload_0
2: getfield #2 // Field i:I
5: iconst_1
6: iadd
7: dup_x1
8: putfield #2 // Field i:I
11: ireturn
当有A,B两个线程同时执行时,JVM实际执行的指令会变成:
A0: aload_0
A1: aload_0
A2: getfield #2 // Field i:I
A5: iconst_1
A6: iadd
A7: dup_x1
B0: aload_0
B1: aload_0
B2: getfield #2 // Field i:I
B5: iconst_1
B6: iadd
B7: dup_x1
A8: putfield #2 // Field i:I
A11: ireturn
B8: putfield #2 // Field i:I
B11: ireturn
- 假设i的初值为i0
- 在A执行从A0到A7时,A已经从内存中取出了i,此时i=i0,并进行了加一操作,但此时没有将i写回内存(
A8: putfield) - 此时JVM切换到线程B执行,B从内存中取出i,此时i=i0,即此时的值与A取出的前值是一样的。
- 在B执行加一操作后,JVM切换到线程A,执行了写回操作(
A8:putfield),此时i的值变为i0+1 - A执行后,JVM切换到B,B同样执行写回(
B8:putfield),此时i的值为i0+1 - 程序的预期是i为i0+2,增加两次,但在这种顺序下,i只增加了一次。
即,这个例子以字节码的形式说明了同步问题的根本所在。
拐言: 这里面其实有很多类似于汇编的原理,喜欢的朋友可以回翻一下8086汇编,食用效果更好
一个误解是通过volatile可以避免上述问题,然并卵
原因在于增量运算符的复合性质。
-
即使用
volatile后并不会改变上述字节码的问题。 -
可以用
synchronized来解决。
测试是检测错误的存在,而不是没有错误
—-Dijkstra
12.2 理解JMM
现代处理器的简化架构如下图:
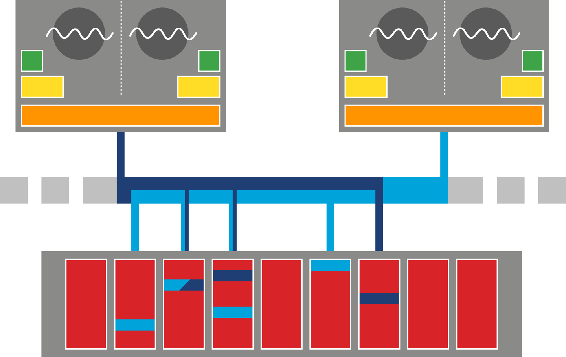
其中:
- 绿色 - CPU的L1-Cache 即一级缓存,单核心内独有
- 黄色 - CPU的L2-Cache 即二级缓存,单核心内独有
- 橙色 - CPU的L3-Cache 即三级缓存,一个CPU内的不同核心共占
- 红色 - 主存、即内存,显然,这是多个CPU共用的。
而只要涉及到分层存储,就要处理不同层级之间的一致性问题。
如在图中,两个CPU把一块数据从主存读取到各自的L3,那么怎么保证两个CPU在各自修改数据后写回的数据是一致的。 再进一步,如果在第一个CPU中,两个核心把L3的数据分别读到各自的L2,又如何保证L2写回L3是一致的。
书中只是放了一个图,大概是猜读者都有计算机原理相关的知识背景吧,直接读上下文很容易一头雾水
同上面这种问题,可以得出
内存模型可以分为两种:
- 强内存模型(strong memory model) 所有核心在任何时候看到的值总是相同的
- 弱内存模型(weak memory model) 不同的核心可能会看到不同的值,有特殊的缓存规则控制这种情况出现的时机
JMM是Java的内存模型,并在JSR 133进行了大量修改,与Java5一起交付。
JSR 133 可以参见参考条目2
JMM试图解决以下问题:
- 当两个处理器核心访问相同的数据时会发生什么;
- 什么时候能保证它们看到的是相同的;
- 内存缓存对这些有什么影响。
JMM能做到的保证为:
- 与排序相关的保证
拐言: 这里应该是指指令的顺序
- 与跨线程更新可见性的保证
JMM保证的基本概念
- 先行发生 ———— 一个事件确定在另一个事件之前发生
- 同步 ———— 事件将导致其对象的视图与主内存同步
- 类串行 ———— 指令在执行线程之外看上去是按顺序执行的
- 先释放,再获取 ———— 锁要先被革个线程释放,之后才可以被下一个线程获取
处理共享的可变状态是通过同步进行锁定的,这是Java并发性视图的一个基本组成。
每个线程都有自己的状态,对对象所做的改变都要在写回内存后才可以被其他线程读取。
因此,synchronized关键字的用就是表明持有管程(monitor)的线程的本地视图已经与内存同步。
synchronized的局限性:
- 所有
synchronized的对象被平等对待 - 锁的获取和释放操作必须在方法或代码块级别
这里指synchronized的两种位置
- 要么获取锁,要么被阻塞,在上锁失败后没办法执行其他处理。
平等对待经常被忽略,即如果使用synchronized进行写操作,那么读操作应该也为synchronized
Java9 对 JMM进行了进一步的扩展
对于JMM的进一步的了解,可以参考【参考】部分的第3条和第4条
吐槽,越读越感觉此书盛名之下,有点,嗯……
12.3 构建并发库
现代Java并发执行机制如下图所示:
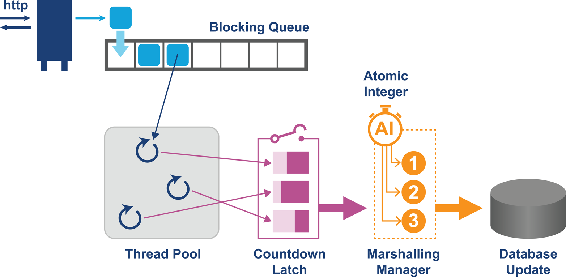
吐槽,作者又扔了一个图然后言他了。。。
图中为一个http请求的一般处理:
- 用阻塞队列接受并发请求
- 用线程池+阻塞队列来处理并发请求
java.util.concurrent是java的核心并发库,提供的模块可以分为以下几类:
- 锁(lock)和信号量(semaphore)
- 原子(atomic)
- 阻塞队列(blocking queue)
- 锁存器(latch)
- 执行器(excutor)
其中很多实现(比如锁和原子)用了CAS技术
CAS (Compare and Swap)
实现步骤:
- 将预期值与内存中的值进行比较
- 如果匹配,则替换为新值
CAS在现代处理器上一般由硬件提供实现,也有操作系统会提供类似支持
- CAS并不是JAVA或JMM规范的一部分
- CAS被视为依赖于特定扩展(即依赖于硬件)的实现
- 因为1&2,CAS是由
sun.misc.Unsafe提供
这个推论。。。。。
12.3.1 Unsafe
- 不是标准JDK的一部分
- 使用会导致与HotSpot产生直接耦合
- 在JDK9中,位于
jdk.unsupported中 - 在最新的LTS-JDK17中,位于
jdk.internal.misc中
其源码说明如下:
A collection of methods for performing low-level, unsafe operations. Although the class and all methods are public, use of this class is limited because only trusted code can obtain instances of it. Note: It is the responsibility of the caller to make sure arguments are checked before methods of this class are called. While some rudimentary checks are performed on the input, the checks are best effort and when performance is an overriding priority, as when methods of this class are optimized by the runtime compiler, some or all checks (if any) may be elided. Hence, the caller must not rely on the checks and corresponding exceptions!
提供的操作如:
- 分配一个对象,但不运行它的构造器,如
allocateInstance - 访问原始内存和执行相当于指针的运算功能,如
getAddress - 使用处理器硬件特性,如CAS操作
并支持如下高级特性:
- 快速序列化/反序列化
- 线程安全的原生内存访问
- 原子内存操作
- 高效的对象/内存布局
- 定制内存屏障
- 和原生代码快速交互
- JNI的多操作系统替代品
- 使用volatile语义访问数组元素
12.3.2 原子与CAS
原书中例子是一个demo,为了食之有味,咱直接撸一下ConcurrentHashMap中原码 !!
下面是ConcurrentHashMap中的initTable方法,主要用于初始化哈希桶
private static final Unsafe U = Unsafe.getUnsafe();
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* creation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
*/
// hash桶的大小
private transient volatile int sizeCtl;
// 得到sizeCtl字段在ConcurrentHashMap这个Object的内存块中的偏移,即**相对地址**
private static final long SIZECTL s= U.objectFieldOffset(ConcurrentHashMap.class, "sizeCtl");
//Initializes table, using the size recorded in sizeCtl.
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSetInt(this, SIZECTL, sc, -1)) {
// sc 最开始为0 ,sizeCtl也为0
// 关键的地方,比较当前sizeCtl(即 内存基地址为this,偏移为SIZECTL)的值是否为sc,如果不是,就设置成-1
// 如果是sc表示已经初始完成
//在设置成-1后,因为sc必是>=0的,所以如果有其他线程调用initTable,肯定不会进行到这里
try {
if ((tab = table) == null || tab.length == 0) {
//得到默认大小 DEFAULT_CAPACITY 16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
// 在这里设置sizeCtl为sc,此时已经初始化完成。
sizeCtl = sc;
}
break;
}
}
return tab;
}
从这个代码可以看到,使用CAS操作
- 需要进行反复重试(while操作)
- 重试过程中无等待
12.3.3 锁和自旋锁
自旋锁(SpinLock): 当锁失败后反复进行重试取得锁,直到成功为止
自旋锁大多以CAS实现
其核心概念:
- 测试并设置(test and set)的操作必须是原子的
- 如果对自旋锁有争用,那么正在等待的处理器会执行一个紧凑的循环
12.4 并发库总结
12.4.1 java.util.concurrent.Lock
lock()以传统的方式获得锁newCondition()创建和这个锁有关的条件,支持更灵活的使用该锁tryLock()尝试获取锁,可以指定超时时间,允许在线程在锁不可用的情况继续其处理unlock()释放锁
主要实现为ReentrantLock,使用了一个int的compareAndSap()
所以锁的获取是无锁的。
一个线程可以获取相同锁,即所谓的可重入锁
可重入锁可以防止线程把自己阻塞
- ReentrantLock使用Unsafe的方法在其静态子类
Sync中 Sync继承自AbstractQueuedSynchronizerAbstractQueuedSynchronizer中使用了LockSupport类LockSupport支持线程的挂机和恢复
LockSupport通过向线程发放许可来工作,如果没有有效许可,线程则等待。
该方法取代了Thread.suspend()和Thread.resume()
LockSupport的等待的调用为park,也是通过Unsafe来实现。
具体:
park(Object blocker)阻塞,直到另一个线程调用unpark()对blocker的上锁通过
Unsafe.putReferenceVolatile实现park(Object blocker,long nanos)与park相同,经过指定时间会返回超时机制在
Unsafe.park中实现- `parkUntil(Object blocker,long)
超时机制在
Unsafe.park中实现
Sync.tryLock方法,值得一读:)
//An annotation expressing that a method is especially sensitive to stack overflows
@ReservedStackAccess
final boolean tryLock() {
Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, 1)) {
// 自旋锁
setExclusiveOwnerThread(current);
return true;
}
} else if (getExclusiveOwnerThread() == current) {
if (++c < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(c);
return true;
}
return false;
}
12.4.2 读写锁
ReentrantReadWriteLock提供了ReadLock和WriteLock
关键实现:
ReadLock.lock
private final Sync sync;
public void lock() {
sync.acquireShared(1);
}
WriteLock.lock
private final Sync sync;
public void lock() {
sync.acquire(1);
}
所以关键还是要多研究Sync
用法:
public class AgeCache {
private final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
private final Lock readLock = rwl.readLock();
private final Lock writeLock = rwl.writeLock();
private Map<String, Integer> ageCache = new HashMap<>();
public Integer getAge(String name) {
readLock.lock();
try {
return ageCache.get(name);
} finally {
readLock.unlock();
}
}
public void updateAge(String name, int newAge) {
writeLock.lock();
try {
ageCache.put(name, newAge);
} finally {
writeLock.unlock();
}
}
}
12.4.3 信号量
信号量提供了一种技术,支持访问多个可用的资源,如池中的线程或数据连接
信号量工作的前提是,最多有X个对象允许访问
//支持最多两个许可的信号量
//第二个参数表示使用公平模式
//公平模式指的是遵循先进先出原则
private Semaphore poolPermits = new Semaphore(2, true);
Semaphore::aquire()将许可数减少一个,即获得一个Semaphore::release()返回一个许可,即释放一个。
Semaphore内部有两个类分别实现公平模式和非公平模式
public Semaphore(int permits, boolean fair) {
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}
/**
* Synchronization implementation for semaphore. Uses AQS state
* to represent permits. Subclassed into fair and nonfair
* versions.
*/
abstract static class Sync extends AbstractQueuedSynchronizer {
final int nonfairTryAcquireShared(int acquires) {
for (;;) {
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
// common code
}
/**
* NonFair version
*/
static final class NonfairSync extends Sync {
private static final long serialVersionUID = -2694183684443567898L;
NonfairSync(int permits) {
super(permits);
}
protected int tryAcquireShared(int acquires) {
return nonfairTryAcquireShared(acquires);
}
}
/**
* Fair version
*/
static final class FairSync extends Sync {
private static final long serialVersionUID = 2014338818796000944L;
FairSync(int permits) {
super(permits);
}
protected int tryAcquireShared(int acquires) {
for (;;) {
// 如果没有可用进程,直接饿死
// 这里是与NonfairSync的区别
if (hasQueuedPredecessors())
return -1;
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
}
- 只有一个许可的信号量等价于互斥量(Mutex)
- 区别: Mutex 只能由加锁的线程释放,而Semaphore可以由并不拥有它的线程来释放
- 使用多个许可可以采用公平模式,否则会增加线程饿死的机会。
看着像是面试题的样子。
12.4.4 并发集合
- ConcurrentHashMap
- CopyOnWrteArrayList & CopyOnWriteArraySet 任何更改都会创建一个新的副本,用这种方式确保一致性。
哪个并发集合都可以单独写上一篇,so这里简略了,先欠着
12.4.5 锁存器和屏障
- 锁存器用于等待N个子任务执行完成后执行N+1的情况
- 锁存器在计数归零后不可再复用。
锁存器在启动时的自动缓存填充和多线程测试等情况下非常有用。
示例代码:
public class LatchExample implements Runnable {
private final CountDownLatch latch;
public LatchExample(CountDownLatch latch) {
this.latch = latch;
}
@Override
public void run() {
// Call an API
System.out.println(Thread.currentThread().getName() + " Done API Call");
try {
// 计数减一
latch.countDown();
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()
+ " Continue processing");
}
public static void main(String[] args) throws InterruptedException {
//计数为5
CountDownLatch apiLatch = new CountDownLatch(5);
ExecutorService pool = Executors.newFixedThreadPool(5);
for (int i = 0; i < 5; i++) {
pool.submit(new LatchExample(apiLatch));
}
System.out.println(Thread.currentThread().getName()
+" about to await on main..");
apiLatch.await();
System.out.println(Thread.currentThread().getName()
+ " done awaiting on main..");
pool.shutdown();
try {
pool.awaitTermination(5, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("API Processing Complete");
}
}
输出如下
pool-1-thread-1 Done API Call
pool-1-thread-3 Done API Call
main about to await on main..
pool-1-thread-5 Done API Call
pool-1-thread-4 Done API Call
pool-1-thread-2 Done API Call
pool-1-thread-2 Continue processing
pool-1-thread-1 Continue processing
pool-1-thread-3 Continue processing
pool-1-thread-5 Continue processing
main done awaiting on main..
pool-1-thread-4 Continue processing
API Processing Complete
12.5 执行器和任务抽象
12.5.1 认识异步执行
- 实现并行任务的一个方式是使用
Callable接口来表示有返回的任务 Callable定义了一个call方法,用以返回结果,失败时抛出异常Runnable即不会返回结果,也不会抛出异常
如果Runnable抛出了一个未被捕获的异常,那它会在栈中传播,其线程会停止运行
拐言,也就是说尽量别用Runnable呗
Callable的实现通过ExecutorService的submit()方法提交执行。
ExecutorService是一个接口,定义了在一个托管的线程池上执行任务的机制,而其实现定义了线程池如何管理及应该有多少个线程。
ExecutorService的具体实现通过辅助类Executors的一系列new*工厂方法来得到。
其中具体如下:
-
newFixedThreadPool(int n)构造一个具有固定大小的线程池,其线程被重复使用以运行多个任务,当所有线程都在使用时,新的任务会被保存在一个队列中。任务队列为阻塞队列
LinkedBlockingQueue newCachedThreadPool()根据需要创建新的线程,并尽可能重复使用线程,已经创建的线程会在缓存中保留60秒,之后会从缓存中删除,适用于小型的异步任务任务队列为非阻塞队列
SynchronousQueuenewSingeThreadExecutor()底层只有一个线程,所有的任务都会被排队,直到线程可用。任务队列为阻塞队列
LinkedBlockingQueuenewScheduledThreadPool()可以接受延迟参数,让任务在未来的某个时间点执行。
任务的返回
- 任务提交后会返回
Future - 通过
Future::get得到Callable::call的结果,阻塞式 - 通过
Future::isDone()判断Callable是否执行完成,非阻塞式
12.5.2 选择一个ExecutorService
对ExecutorService调优的一个关键指标是线程数量与CPU核心数量的对比
- 线程数>CPU核心 引起并发争用
12.5.3 Fork / Join
Fork/Join
- Java7引入的框架
- 可以有效配合多个处理器工作
实现方式
- 基于ExecutorService的ForkJoinPool实现
- 对细分任务的支持通过ForkJoinTask实现,类似于线程,比线程更轻量
- ForkJoinTask可以将自己反复细分,直到规模小到可以直接计算
- 该框架适合特定类型的任务
特性
- 可以高效处理细分任务
- 实现了工作窃取(Work-Stealing)算法
工作窃取算法
一个大任务分割为若干个互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并未每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。比如线程1负责处理1队列里的任务,2线程负责2队列的。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务待处理。干完活的线程与其等着,不如帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。 而在这时它们可能会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务线程永远从双端队列的尾部拿任务执行。
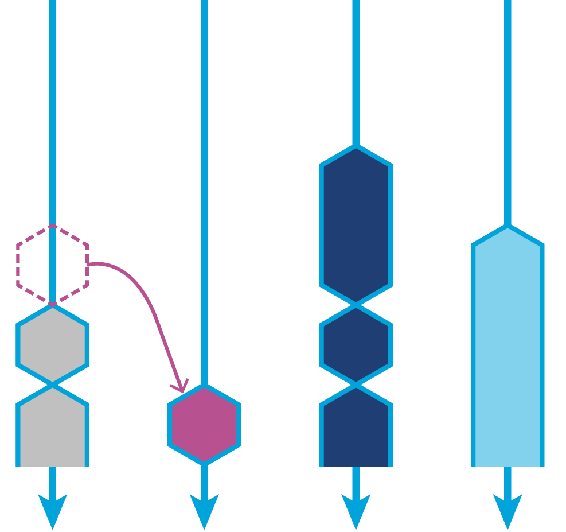
-
可以独立于细分任务使用
-
ForkJoinPool有一个静态方法commonPool(),返回系统级的池引用,同时这个池是惰性的,使用时才会创建
- 让开发人员不必创建/关注自己的线程池
- 为共享提供了机会
- 池的大小
Runtime.getRuntime().avaliableProcessors()-1
- 拐言: 似乎可以撸一下ForkJoinPool和ForkJoinTask的源码,然而此时此刻本文已经一万七千字了,如果把源码贴上来估计更没有人看了。。
- 记个Todo
- 本文Todo有点多。。
关于Runtime.getRuntime().avaliableProcessors()
这个方法未必能返回预期结果。
虚拟机并不是真的的知道处理器是什么,它只是向操作系统询问一个数字。同理,操作系统也不会在意,它会询问硬件。硬件会回应一个数字,通常是”硬件线程”的数量。 操作系统相信硬件,虚拟机相信操作系统。 —-Brian Goetz
可以更改预置的并行度
-Djava.util.concurrent.ForkJoin.Pool.common.parallelism=128
慎用哦~~
12.6 现代Java并发
冷知识:Java是第一个在语言级别内置了线程支持的工业级标准环境
原文:Java一般不会废弃特性(尤其是核心特性),所以Thread API仍然是Java的一部分,并且永远都是
- 因为是工业级,所以已经有的不会被干掉
- Thread API 这么遭嫌弃嘛,是挺招人厌的哈
12.6.1 流和并行流
- 从Java8开始引入Lambda流
- 流是一个不可变的数据项序列,可以来自任何数据流
- 所有Collection的集合都提供了stream方法,其提供了一个创建流的实现,并在背后创建了一个ReferecePipeline
并行流
- 方法是parallelStream()
- 可以并行处理数据组合结果
- parallelStream使用一个Splierator对工作进行分解,并在公共的Fork/Join上进行计算
在较小的集合上,串行流计算可能会更快
使用parallelStream请做充足的测试以保证性能
12.6.2 无锁技术
Disruptors模式
Disruptor是一个高性能的异步处理框架,或者可以认为是最快的消息框架(轻量的JMS),也可以认为是一个观察者模式实现,或者事件-监听模式的实现,直接称disruptor模式。disruptor最大特点是高性能,其LMAX架构可以获得每秒6百万订单,用1微秒的延迟获得吞吐量为100K+
Disruptor本质上是通过volatile变量来实现的自旋锁
private volatile int proceedValue;
//...
while (i != proceedValue) {
// busy loop
}
- CPU收到信号可以立刻执行,没有上下文切换的成本
- 忙循环会导致功耗和发热
- 使用这种机制要求程序员对机器有着底层的理解,即机械共鸣
机械共鸣 最佳车手对机器如何工作有足够的理解,所以可以与塞车协调一致
12.6.3 基于Actor的技术
Actor范型(Actor Paradigm)
- Actor是小型的,自包含的处理单元,有自身的状态,行为及用来与其他Actor通信的邮箱系统(MailBox)
- Actor的思路是不共享任何可变状态,只通过不可变的消息通信
- 通信是异步的
- 可以在一个进程里,也可以跨多台机器
- 通常有一个快速失败的策略
Akka是基于Actor系统的一个流行框架,其用scala实现,同时提供了java api
使用Akka的核心动机
- 领域模型内封装可变状态非常棘手,尤其内部对象的引用在不受控制的状态下逃逸时
- 锁会导致吞吐量下降
- 锁可能导致死锁或其他活跃性问题
底层API没有线程失败或恢复的标准方法,而Akka对其进行了优化
参考
-
百度百科:Amdahl定律 https://baike.baidu.com/item/%E9%98%BF%E5%A7%86%E8%BE%BE%E5%B0%94%E5%AE%9A%E5%BE%8B
-
JSR-133 下载 JSR-133
-
The JSR-133 Cookbook for Compiler Writers https://gee.cs.oswego.edu/dl/jmm/cookbook.html
-
Close Encounters of The Java Memory Model Kind https://shipilev.net/blog/2016/close-encounters-of-jmm-kind/
-
CSDN - 什么是工作窃取算法 https://blog.csdn.net/dongcheng_2015/article/details/120313784
-
cnblogs - Disruptor入门 https://www.cnblogs.com/linjiqin/p/7436034.html
-
akka https://github.com/akka/akka
关于老拐瘦
中年争取不油不丧积极向上的码农一名
咖啡,摄影,骑行,音乐
样样通,样样松
喜欢可以关注一下公众号 IT老拐瘦

目前个人博客长驻: yfge.github.io