一个完全不懂 GEO/SEO 的人:半天上线、三天出现收录信号、最后决定开源
一个完全不懂 GEO/SEO 的人:半天上线、三天出现收录信号、最后决定开源
我先把底牌亮出来:我对 GEO、SEO 基本是一窍不通。 别说什么“关键词密度”“结构化数据”“站群策略”,我以前听到这些词,第一反应是——这玩意儿靠谱么?会不会是玄学?
但现实是:我做了个站,上线后没几天就出现了 Google 侧“开始收录/开始出索引”的信号。 更离谱的是(至少在我当时看到的早期数据里):搜索入口不是先进首页,而是更常落在详情页上。
为了避免“我觉得”式自嗨,我把能公开、也能被验证的点列出来:站点对爬虫是可抓取、可枚举的——
- 有
robots.txt - 有 sitemap index(
sitemap-index.xml/sitemap.xml),能把页面集合“交代清楚” - 主页与详情页都有结构化数据(JSON-LD),降低理解成本
- 还有
llms.txt/llms-full.txt这类面向 LLM/agent 的索引文件
至于“收录速度/流量结构”的结论,如果想更严格,还是以 Search Console 的数据为准;我这里写的是当时观察到的信号与趋势(下面两张图就是当时的截图口径)。
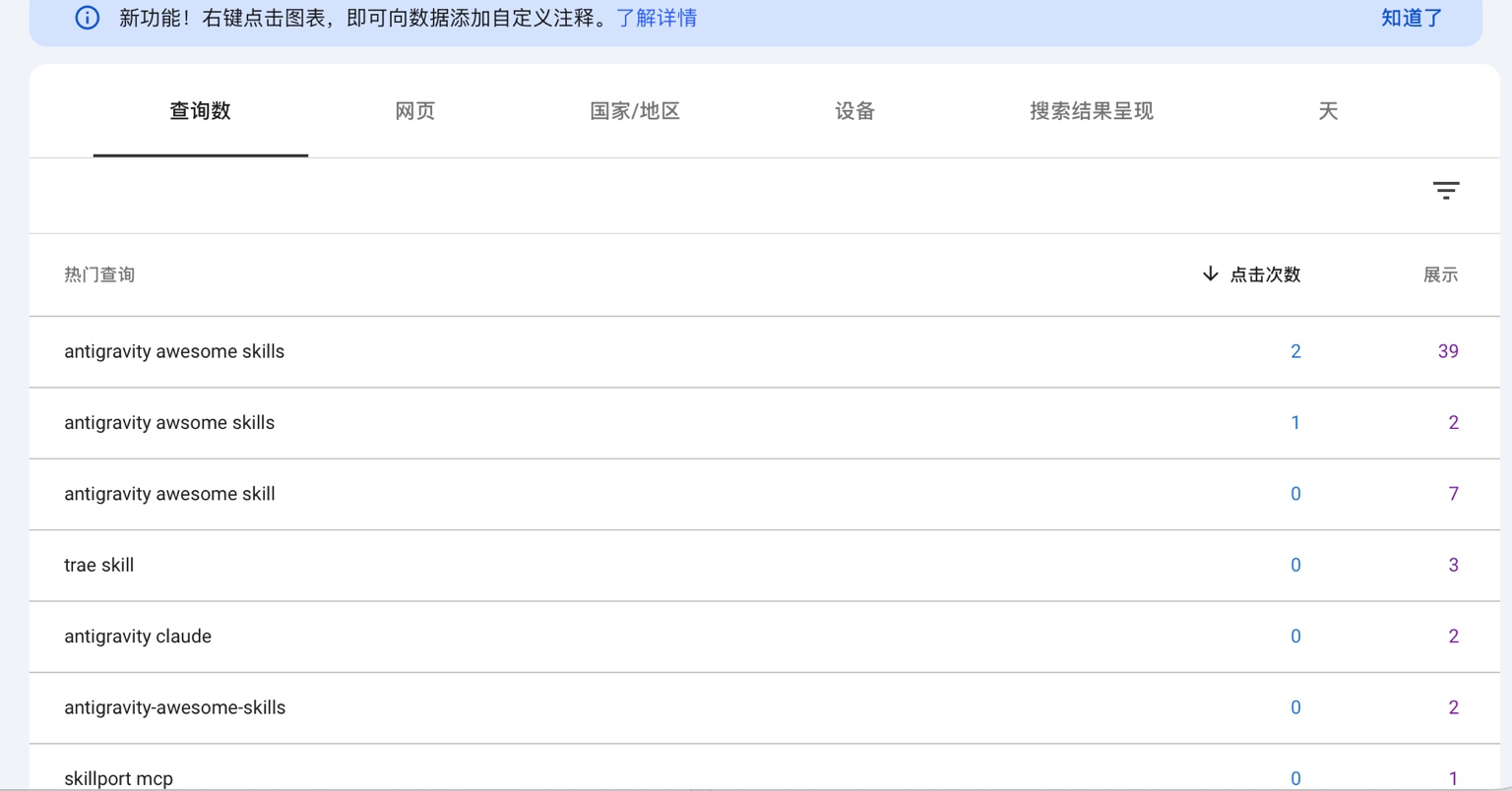
Google Search Console 的效果概览(截图口径:近 3 个月)。
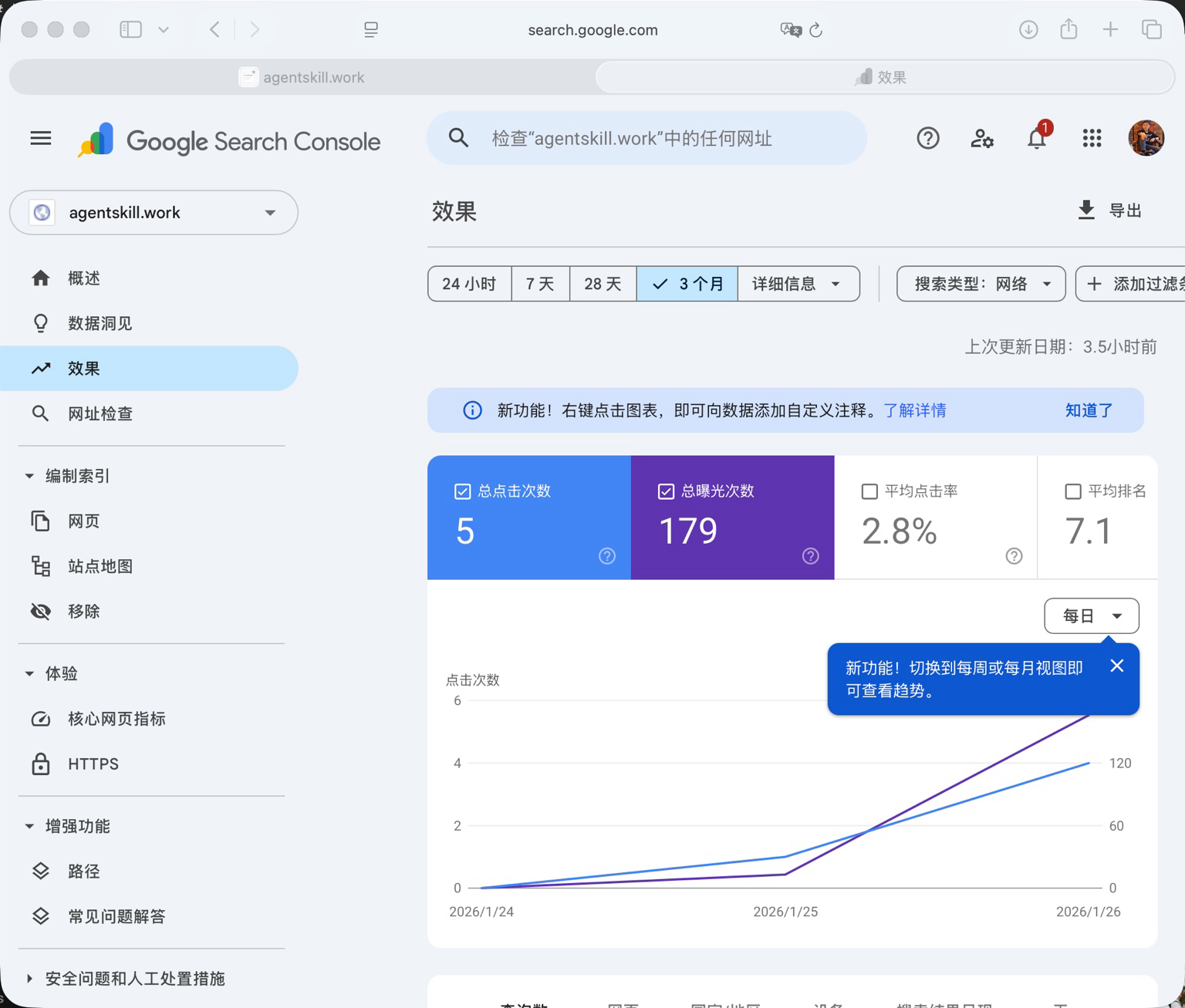
Google Search Console 的热门查询列表(能看到一些长尾词已经开始出现展示/点击)。
站叫 agentskill.work,项目也已经开源:
这篇不是技术教程(那个我已经写过了)。 我想写的是更“老登”的那部分:一个完全不懂 GEO/SEO 的人,到底做对了什么,才没翻车。
1)我不是“会 GEO/SEO”,我只是“怕系统”
这句话可能有点怂,但真的:我不自信。
AI 现在太猛了:Cursor、Claude、Codex……写代码、改代码、补功能,快到让人怀疑人生。 所以很多人会走到一个很危险的状态:
“能跑了,差不多就行。”
老登的直觉是反过来的: 能跑,只代表它“这一次”没死。上线之后,它随时可能换一种方式死给你看。
所以我一开始就没打算“证明我懂”,我打算“证明它是真的能被验证”。
2)敬畏系统:不只是线上系统,更是我不懂的知识系统
很多人谈“敬畏系统”,第一反应是线上系统: 流量、并发、缓存、证书、日志、监控……这些东西确实会反噬你。
但我这次更大的体感是:还要敬畏另一种系统——知识系统。 比如 SEO,比如 GEO。
这里我顺手把“GEO”说清楚:我在文里说的 GEO 更接近 Generative Engine Optimization(面向“生成式搜索/LLM 引擎”的可发现性优化)。它和传统 SEO 有大量重叠:结构化数据、可枚举的 URL、稳定的 canonical、清晰的信息架构……本质都是在降低“抓取/理解/索引”的成本,只是服务的消费端从“搜索引擎结果页”扩展到了“LLM 的答案生成”。
AI 不是“给你超能力”,AI 更像是“给你一把电钻”。 你拿着电钻,不代表你就会盖房子,你最多只是把洞打得更快。
所以真正的分水岭不是“我会不会问 AI”,而是:
- 你承不承认:我不懂,我得学
- 你愿不愿意:反复探索、反复验证、反复纠错
- 你有没有耐心:用结果证明,而不是用感觉安慰自己
不懂不可怕,可怕的是你以为自己懂了。
3)我做的不是一个站,是一套“关键节点把控”
站本身很简单,你说得对:换个关键词、换个域名,就是另一个 GitHub 聚合站。 真正决定它能不能活下来的,不是页面好不好看,而是关键节点你有没有掐住。
我做的“老登操作”大概就这些(我尽量不讲技术名词):
- 外部数据别把自己拖死:抓取这件事要有节奏、有护栏,不能想抓就抓。
- 任务要可控:该定时就定时,该排队就排队,别靠“用户访问时顺便做”。
- 工具选型要能扛事:AI 一开始想给我上更“优雅”的方案,我直接拍板用我更熟、出了事更好定位的那套。
- 上线第一天就要看得见数据:我甚至把 Umami 也搭了,目的不是炫技,是为了别靠感觉活着。

Umami 的页面路径分布(截图口径:按路径聚合的访问量)。
你看,全是很无聊的东西。 但它们背后是一句话:我不信系统会乖,所以我要提前加护栏。
4)我验证 GEO/SEO 的方式:不是“我觉得”,而是“它真的能被验证”
这里是最笨、也最关键的部分。
我对 GEO/SEO 不懂怎么办?我就问 AI。 但我不是问一次就信——我做了一个很“笨”的循环:
- 我问 ChatGPT:现在抓取能看到内容吗?SEO/GEO 友好吗?
- ChatGPT 指出问题:哪里不一致、哪里像空壳、哪里会影响抓取。
- 我把这些建议原封不动贴给 Codex:让它照着改。
- 我再回到 ChatGPT 复核:现在行了吗?
- 直到它给出“基本可以”的判断。
注意,这里最重要的不是“我说可以”,而是“反复复核之后依然说得通”。 因为人最容易骗自己:
“差不多了吧” “应该行吧” “先上线再说吧”
我不敢。我只信“可验证结果”,而不是“主观感觉”。
说白了:我不是在“问 AI”,我是在让 AI 帮我建立一个可重复的学习循环。
5)结果来了:搜索入口不是“可怜地进首页”,而是“更常命中详情页”
这件事对我意义很大。
很多新站被收录之后,最常见的情况是: Google 给你一点“站名词”的流量,用户点进首页,看两眼就走。
而我看到的是(结合上面的 Search Console 截图,以及后面 Umami 的路径分布):搜索入口会直接落到某个具体 repo 的详情页上——这通常意味着这页在信息结构上更“像答案”,更容易被拿来承接长尾查询(注意:这是一种经验判断,不是严格因果)。
对一个目录/聚合站来说,这就是最好的一种起势: 不是靠首页撑门面,而是靠大量详情页吃长尾。
这也让我更确信:我这套“反复验证 + 护栏优先”的方式是对的。
6)开源与否:我纠结过,但最后还是开了
我纠结的点很现实:
“这东西太容易复刻了,开源不就是送?”
但想明白之后,我发现开不开源,挡不住别人做一个‘关键词聚合站’。 真正挡不住的,是“复制代码”;真正复制不了的,是:
- 你是怎么把系统从 0 驯服到可上线的
- 你是怎么在关键节点做判断的
- 你是怎么把 AI 当施工队、自己当监理的
- 你是怎么用数据闭环逼自己不自嗨的
从个人 IP 的角度,开源反而更合理: 代码不是护城河,能交付、能把控、能复盘的能力才是。
所以我开源了。 反正“抄”不可怕,可怕的是你自己没有迭代速度和判断力。
7)最后的收尾:不自信,敬畏系统的人,才有未来
AI 时代,程序员确实每天都在担心自己被替代。 最近半年,从 Cursor 到 Claude,再到 Codex,我更强烈的感觉是:
写代码这件事会越来越便宜,甚至会出现“程序员断层”。 但系统不会消失,复杂度不会消失,线上事故不会消失。
所以我越来越相信一句朴素的话:
不自信,敬畏系统的人,才有未来。
不自信不是怂,是你看到“能跑”时会本能多问一句: “它为什么能跑?上线后还会不会这么跑?”
敬畏系统不是保守,是你知道复杂度会复利增长, 你今天省下的一点点侥幸,未来会在某个凌晨三点连本带利还回来。
AI 会让“写代码的人”越来越多。 但能把系统跑稳、把关键节点掐住的人,会越来越贵。
如果你也准备做一个“主题站引擎”,我的建议就一句: 别急着炫技,先把护栏立起来;别急着觉得自己懂,先让结果可验证。